Our project 5 may have been posted by another group member (Thom, Katie or Sarah) but I wanted to post it to my blog so that I have a copy of it kept here. We answered option 2 and the link can be found here.
Post 15: Project 4
Our group watched Ex Machina and reviewed it in a podcast. You can find the link here.
Post 14: Censorship
It was really interesting to me to see how China went about censoring the internet and enforcing the restrictions. I thought the article, “Cracking the ‘Great Firewall’ of China’s Web censorship” gave a lot of information to help better understand why governments limit speech, how they go about it and what the implications are. The article said how China has technically the worlds most sophisticated internet filtering systems, according to the OpenNet Initiative, and that it is much easier for Chinese authorities to monitor all the traffic into and out of the Chinese web. This is because all of the data comes into China through 3 cities whereas in the U.S. data is coming in and out of many various locations. In this way, government officials are able to monitor and police what is entering and exiting the country. The government also demands self-censorship, and enforces heavy censorship controls on the local companies.
Demanding self-censorship. Chinese authorities hold commercial websites responsible for what appears on them. In Beijing — where Internet controls are strictest — authorities issue orders to website managers through cellphone text messages and demand that they comply within 30 minutes, according to a report last fall by Reporters Without Borders.
It is interesting to consider the Yahoo! case and how it affects individuals that are not even in the country. In the article, “Yahoo! in China – Background” it took serious consideration on what Yahoo! has been doing and what it should be doing.
Yahoo!’s own later public admissions, Yahoo! China provided account-holder information, in compliance with a government request, that led to Shi Tao’s sentencing.
Governments around the world are asking companies, including Yahoo!, to comply with their efforts to repress people’s rights to freedom of expression and privacy. Companies must respect human rights, wherever they operate, and Yahoo! must give adequate consideration to the human rights implications of its operations and investments.
The thing is, Yahoo! does not have the right to repress anyones freedom just as much as unjust governments do not. I think it is good to note that Yahoo! has started to make steps to amend this process and change their involvement. I think to some degree at this present time companies like Yahoo! have the ability to be influential on the political sphere in helping ensure human rights, and that it is their duty to do so.
Finally, Yahoo! should not consider it an option to arrange a business relationship with a Chinese Internet company and then cite its own lack of control over its operations as an excuse for not taking pro-active steps to stop involvement in abuse of freedom of expression or privacy rights. But, on more than one occasion, Yahoo! has cited its relationship with Alibaba (Alibaba controls Yahoo! China in exchange for Yahoo!’s 40% ownership share of Alibaba) to explain its lack of ability to resist government requests for user information.
That is why we are supporting the Global Online Freedom Act, which is designed to respond to and prevent censorship and abuse of freedom of expression on the Internet by placing restrictions on U.S. Internet content hosting companies operating in countries that censor, prosecute and/or persecute individuals based on the exercise of such freedoms.
I definitely think that censorship is a major concern. Even though we may not experience intensive censorship, does not mean its not there or not harmful. As Martin Luther King Jr. once said, “Injustice anywhere is a threat to justice everywhere.” I think it is important to think more with those guidelines. Censorship is dangerous, and something that we do not want to spread. In that case, it is a concern that it exists at all.
Post 13: Intelligence
In the article, “What is artificial intelligence?” I read that:
Simply put, artificial intelligence is a sub-field of computer science. Its goal is to enable the development of computers that are able to do things normally done by people — in particular, things associated with people acting intelligently.
But there is still the idea that it is much more complex than this. There is a range from a strong AI to a weak AI, a narrow AI and a general AI. When it comes down to it, an AI doesn’t have to function in the same way that humans do. It could have the range and not the depth, or have the depth in a particular area but no the range. The thing is, it just has to be smart, and that could look differently in many different machines.
I think there is too much of a hype for what artificial intelligence actually is. I think people believe that it has to be just like a human to be artificial intelligence. Instead, I think it should be evaluated more as any type of intelligence that can be programmed. So theses “tricks” or “gimmicks” really are an example of artificial intelligence. In the article, “How Google’s AlphaGo Beat a Go World Champion” it commented on how the AlphaGo takes a lot of human intelligence and piles it together at every game:
If AlphaGo had lost to Lee in March, it would only have been a matter of time before it improved enough to surpass him. Go is constantly evolving. What’s considered optimal play changes quickly. Humans have been honing our collective knowledge of the game for more than 2,500 years—the difference is that AlphaGo can do the same thing much, much faster.
It also talks about promising steps for AI’s in the future in “Is AlphaGo Really Such a Big Deal?”:
We have learned to use computer systems to reproduce at least some forms of human intuition. Now we’ve got so many wonderful challenges ahead: to expand the range of intuition types we can represent, to make the systems stable, to understand why and how they work, and to learn better ways to combine them with the existing strengths of computer systems. Might we soon learn to capture some of the intuitive judgment that goes into writing mathematical proofs, or into writing stories or good explanations? It’s a tremendously promising time for artificial intelligence.
In response to if the Turing Test is a valid measure of intelligence I think the answer to that is in relation to what we consider intelligence. There are many different ways to evaluate it and many pros and cons. The article “Computing Machinery and Intelligence” explains the reasoning behind it:
I propose to consider the question, “Can machines think?” This should begin with definitions of the meaning of the terms “machine” and “think.” The definitions might be framed so as to reflect so far as possible the normal use of the words, but this attitude is dangerous, If the meaning of the words “machine” and “think” are to be found by examining how they are commonly used it is difficult to escape the conclusion that the meaning and the answer to the question, “Can machines think?” is to be sought in a statistical survey such as a Gallup poll. But this is absurd. Instead of attempting such a definition I shall replace the question by another, which is closely related to it and is expressed in relatively unambiguous words.
While the article “The Turing Test Is Not What You Think It Is” goes further to understand what the Turing test really is trying to investigate:
Good points, all, but they miss the point. It was never Turing’s aim to devise an empirically robust way of telling whether someone or something is really thinking.Can a machine think? For Turing that question was, as he wrote, “too meaningless to deserve discussion.” What is “thinking” anyway? We can hardly hope to make that notion precise.
There is a huge issue with the idea that a computing system could be considered a mind. If so, does turning off a machine constitute killing it? What ethical complications would arise if AI’s got to that point? I think it is interesting to consider the idea that was brought up in “2015 : What do you think about machines that think?” where there could be two separate societies. I think it would be a lot easier on an ethical standpoint if we consider humans not biological computers and computing systems not minds, but if that is the trend that will be taken it is important to be able to lay out the ethical guidelines to deal with these issues.
But wait! Should we also ask what machines that think, or, “AIs”, might be thinking about? Do they want, do they expect civil rights? Do they have feelings? What kind of government (for us) would an AI choose? What kind of society would they want to structure for themselves? Or is “their” society “our” society? Will we, and the AIs, include each other within our respective circles of empathy?
Post 12: Net Neutrality
Since I have written a research paper on Net Neutrality I have decided to attach it below so that you can read it if you would like and see that I have spent time discussing the idea: Essay 2. Other than that I will attach a synopsis of my opinions on the issue below so that it is not necessary to read the essay.
How data is manipulated and presented is a prominent concern, especially regarding the current power dynamic between ISPs, the U.S. government and the users of the Internet. As technology advances, regulation and information segregation becomes easier and more commonplace. The router allows operators to prioritize or de-prioritize certain packets of data or even drop or remove them from their network altogether. This technology continues to evolve and allow operators to choose how to handle data packets for commercial or policy reasons as opposed to the network performance reasons. Packets can be favored because they originate from a preferred source or de-prioritized or even blocked simply because they originate from a non-preferred source. This prioritization or de-prioritization of data packets is often dubbed “access tiering” and it is at the core of the Net Neutrality debate.[1] The ability to handle data on different network tiers has ignited a high-profile debate in the United States about whether or not operators should be allowed to discriminate between data packets and, therefore, whether regulatory intervention is needed to constrain how operators run their networks.[2] Without regulation this opens the door for ISPs to differentiate the data pathways, allowing only some information through at their own discretion. That means an ISP could charge more to stream Netflix versus YouTube, or increase or slow a users browser speed based on price or data plan. This could create a complicated network of business alliances, restrictions on information and socioeconomic disparities. After pushback from the American people, the FCC reconstructed the Open Internet rules and adopted new rules on February 26th, 2015. These rules were designed to protect free expression and innovation on the Internet and promote investment in the nation’s broadband networks. The new rules apply to both fixed and mobile broadband services, recognizing advances in technology and the growing significance of mobile broadband Internet access in recent years. These rules restrict blocking so broadband providers may not block access to legal content, applications and services. It also restricts throttling; broadband providers may not impair or degrade lawful Internet traffic on the basis of content, applications, or services. Further, it restricts paid prioritization or “fast lanes”; broadband providers may not favor some lawful Internet traffic over other lawful traffic in exchange for consideration of any kind.[3] Even though actions have been taken, the concept of Net Neutrality and its place in our society is not resolved.
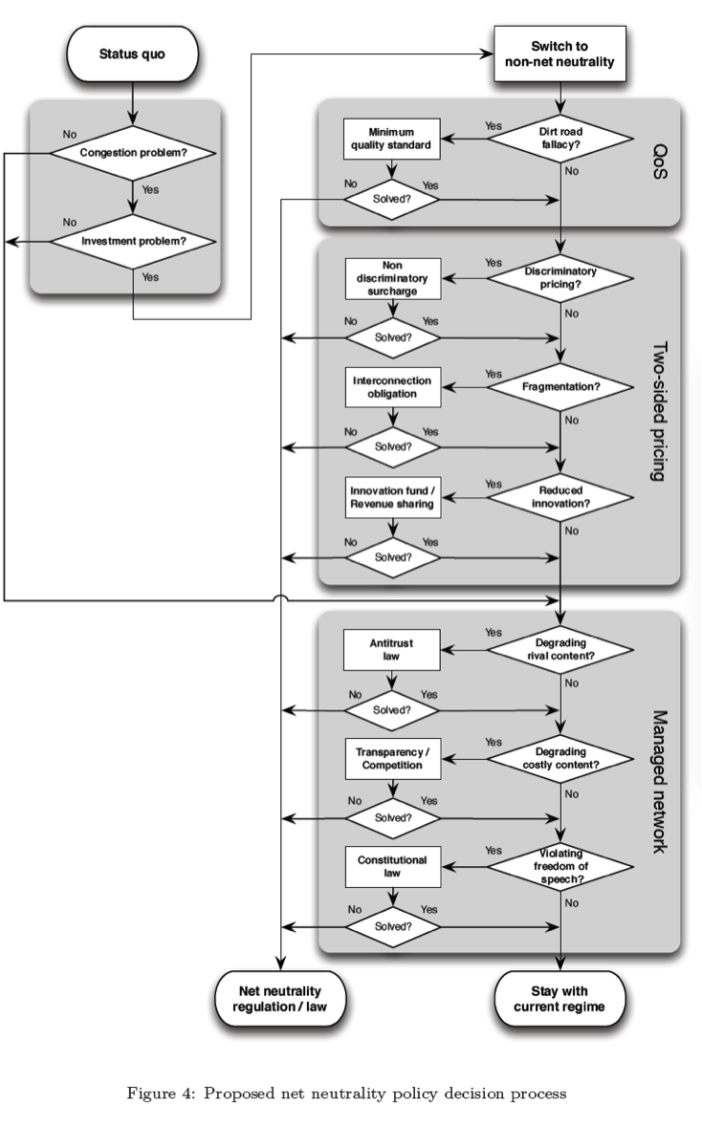
Moving forward with policy, it is important to understand that there must be some regulation of the Internet, and that there is already regulation on the Internet, as it exists today. The question is not whether to regulate cyberspace, but how to do so—within which forum, focusing on which layer, involving which actors, and according to which of many competing values. The regulation of cyberspace tends to take place behind the scenes, based on decisions taken by private actors rather than as a result of public deliberation, without even the knowledge of the public. As the trend toward the securitization and privatization of cyberspace continues, these problems are likely to become more, rather than less, acute.[4] The Net Neutrality rules that are put in place by the FCC are important and must be maintained and improved as the topography of the Internet continues to change. Open access to all content through an open channel is important regardless of medium or type of content. If the engineering behind the physical layer of the Internet changes and tiering must occur, it must be consumer-led, rather than operator-determined, access tiering. It must be matched with meaningful disclosure requirements and contractual protections best balance the reasonable demand that there be an incentive to invest in Internet infrastructure with the public interest in a ‘non-discriminatory’ Internet.”[5] A Net Neutrality policy decision map (See Appendix 2) is important to help understand the steps that must be taken and the process that must follow in order to further address the Net Neutrality debate. The U.S. debate on Net Neutrality has generally been centered on what ISPs could or could not do unless the laws are put into place, which is what they are currently doing at the moment. In this way, it will require a steady raising of awareness, the channeling of ingenuity into productive avenues, and the implementation of liberal-democratic restraints.[6] Even though it is a slow process, actions and legislation must be pushed forward to prevent the upheaval of the Internet instead of waiting for it to be irrevocably changed.
References:
[1] Ganley, Paul and Ben Allgrove. “Net Neutrality: A Users Guide.” 454.
[2] Ganley, Paul and Ben Allgrove. “Net Neutrality: A Users Guide.” 455.
[3] Open Internet. Federal Communcations Commission. May 2, 2015. FCC.gov.
[4] Nissenbaum, Helen. Privacy in Context. 56.
[5] Ganley, Paul and Ben Allgrove. “Net Neutrality: A Users Guide.” 463.
[6] Nissenbaum, Helen. Privacy in Context. 56.
Project 3: Security + Encryption
Our group decided to make a campaign video that informs the public about issues of encryption and security. The project can be found here. Please see my responses to the questions below.
- Is encryption a fundamental right? Should citizens of the US be allowed to have a technology that completely locks out the government?
I think that that this issue sits at the peak in between two very slippery slopes. On one side there is the fear that if the government has a backdoor to a device, it has a backdoor to everyones device. Then, there’s the idea that once the key exists, that it will get into the wrong hands and security as we know it will be gone. There is the other side too, where if we completely lock the government out, illegal activities could rise in the unsupervised and non-policeable domain. I would not want to have either of these scenarios happen. I think encryption is a right, because people should be able to protect their own data without the government watching; however, I think there has to be more restrictions for the platforms themselves to keep out illegal activity.
- How important of an issue is encryption to you? Does it affect who you support politically? financially? socially? Should it?
The issue of encryption is important to me, but I think it could definitely be a lot more important to me. I am not very literate when it comes to politics, but I think that if I learned more about the stances of different politicians on encryption it would make a difference to me. I also think it is important to consider when I think about what companies and resources I give my money to and who I decide to share my data with. I know that data is already being used as a “currency” but I think supporting companies with a strong encryption system and security is very beneficial. Overall, I can see how these topics are very important and I would like to put more time into understanding how I can better prioritize them.
- In the struggle between national security and personal privacy, who will win? Are you resigned to a particular future or will you fight for it?
I think that this question depends on the location of where it is being asked. In many countries around the world I definitely see that national security would overtake the need for personal privacy. I think it is difficult when it comes to the U.S. because the country clearly values national security a lot (with the whole largest military in the world thing) and also really values personal privacy. I really do think that national security will win, but then technology will continue to advance and we will continue to find ways to keep our information private. I do not think there is an ultimatum since I think the way we do things, technology we use, and the things we do will constantly change and evolve. I think that we should fight for what we want, but that we should know that this will be a constant battle.
Post 11: Reverse Engineering, Piracy
The DMCA basically bars reverse engineering and circumvention. The article on the Copyright Act explained that the “anti-circumvention” provisions (sections 1201 et seq. of the Copyright Act) bar circumvention of access controls and technical protection measures. So that these technical protection measures and access controls are lumped together into a sort of “no-zone.”
This is a difficult issue to deal with because there are a lot of different applications of reverse engineering or circumvention that are motivated by many different things and have a wide range of affects. It seems that there is a significant push to change the act as it stands. I read in the article, “Soon It’ll Be OK To Tinker With Your Car’s Software After All” that:
Advocacy group Public Knowledge had requested that the Librarian of Congress allow people to make personal copies of their DVDs, but that petition was rejected. The group says that and other limitations in the ruling show that the DMCA overall needs to be rewritten — something that EFF and other advocacy groups have been pushing for a while.
It was interesting to see that people are now concerned with the preservation of our cultural heritage through digital means and how this act prevents the preservation. It appears that this law also inhibits people who are just trying to preserve the artifact instead of manipulate it, sell it or copy it for their own use. I do not have enough information whether or not this movement is positive or negative because I do not know enough information on whether or not decrypting and allowing information to be used by historians could cause a greater overall breach. Some information and opinions were provided by, “The Copyright Rule We Need to Repeal If We Want to Preserve Our Cultural Heritage” below:
Common wisdom would tell you, “Don’t copy things without permission, and everything will be fine.” But just as DRM-based copy protection prevents unauthorized users from making copies of digital goods, it also prevents cultural institutions from making copies for archival purposes. Every encrypted cultural work is locked, and to get the key, you have to pay the content owner…
The anti-circumvention provision of the DMCA was created primarily to protect DVDs; it did not anticipate our rapid shift to media-independent digital cultural works, so it is absurdly myopic when it comes to digital preservation.
There is also the unrelated issue that John Deere is now trying to tell people they don’t actually “own” their tractor, they are just driving them for the time being. I do not think this is appropriate because it takes away the ability for the owners of these vehicles to be able to fix them. When you originally bought a car, you were able to fix any of the mechanics of it if you had the capability. I do not think that this idea of ownership should change now that there is software involved. I read the article “We Can’t Let John Deere Destroy the Very Idea of Ownership” and saw that they were using a broad statement to enforce a law against a completely different circumstance:
And that’s how manufacturers turn tinkerers into “pirates”—even if said “pirates” aren’t circulating illegal copies of anything. Makes sense, right? Yeah, not to me either…
The pièce de résistance in John Deere’s argument: permitting owners to root around in a tractor’s programming might lead to pirating music through a vehicle’s entertainment system.
I don’t think that this software policing is really beneficial to a lot of people. If the software is in a device that you own, and that software affects the performance of the physical device that you have, I believe that you should be able to alter and fix it on your own. I can see the implication if you do not own certain rights to software that is separate from something you own. But if your tractor is broken, I think you should be able to fix it by yourself.
Post 10: Patent Trolls, Open Source
From the readings, specifically “WIPO – What is IP?”, I have found some of the basic information about patents. I learned that a patent is an exclusive right that is granted for an invention- a product or process that provides a new way of doing something, or that offers a new technical solution to a problem. The idea of the patent is to provide innovators and inventors of these processes protection for their invention. Patents only last for a limited time period. In return for the patent protection, all patent owners are obliged to publicly disclose the information or technical knowledge on this advancement so that it can produce further innovation from others in the future.
I think it is interesting to take Tesla as case study for thinking about the importance of patents. It has now been almost two years since they have released all of their patents. In the article, “All Our Patent Are Belong To You” it explains why they did that:
Tesla Motors was created to accelerate the advent of sustainable transport. If we clear a path to the creation of compelling electric vehicles, but then lay intellectual property landmines behind us to inhibit others, we are acting in a manner contrary to that goal. Tesla will not initiate patent lawsuits against anyone who, in good faith, wants to use our technology.
The idea behind it is that there should not be restrictions to advancing the field in electric vehicles. This makes a lot of sense to me because the goal of the company is to completely change the way the automotive industry works–to change it to a normative electric vehicle standard. Ideally, not having patents would push innovators and create a greater opportunity for advancements to be made. If electric vehicles become more common, Tesla would benefit because owning a Tesla would become more practical with an increase of electric charging stations nationwide. I do not think enough time has passed to understand if this impact has been positive or negative though. Has Tesla been loosing money because other companies can take their technology? Is Tesla advancing above its competitors because now it does not have to publish its technology (by patent law) since it gave away its patents? I think more time could be used to study this to see if it actually improves advancement or hinders advancement.
With regards to patents being granted on software or just restricted to the physical realm, i found some good information in the article, “The Supreme Court doesn’t understand software, and that’s a problem”, as stated:
The problem, at root, is that the courts are confused about the nature of software. The courts have repeatedly said that mathematical algorithms can’t be patented. But many judges also seem to believe that some software is worthy of patent protection. The problem is that “software” and “mathematical algorithm” are two terms for the same thing. Until the courts understand that, the laws regarding software patents are going to be incoherent.
I think it is currently difficult to pinpoint what can be patented, but as inventions continue to become more virtual with the rise in computing capabilities, it is important to protect those that make these inventions. Whether or not traditional patents are the means, I think something should be enacted to provide these protections for the creators of software.
Post 9: Advertising
As the Internet is increasingly expanding and evolving, the question of what the Web looks like and who has control over it comes into play. For a space originally molded after the horizontal, free-thinking example of California culture, the integrity of the Web exists on the foundation that it is innately a borderless, free network.It is interesting to see that the Internet’s utility has changed over the years. Where it was once exploratory, it now seems to a ground for external companies to capitalize on our data unknowingly. That is why I really liked the idea in the article “The Internet’s Original Sin” especially when it pinpoints where the issues could have arisen from:
I have come to believe that advertising is the original sin of the web. The fallen state of our Internet is a direct, if unintentional, consequence of choosing advertising as the default model to support online content and services.
Even though this was unintentional, the consequences of choosing advertising as the main platform to maintain online content changes the internet from its original fundamental purpose and culture. I think it is important to investigate why our data is the main capital that is extracted on the internet today from many services. In the article “How Companies Learn Your Secrets” I saw that when we think something is ‘free’ on the internet, it is really not true. Nothing is free in life; instead, companies are taking your data instead of your money.
“Free is a good price,” Pew said in its report. People like no-cost services, and are willing to forfeit some privacy in exchange for them. An individual’s data has become its own kind of currency. One survey respondent, referring to his use of Gmail, said: “To be honest, I don’t really care … I use Gmail for free, but I know that Google will capture some information in return. I’m fine with that.”
As it said in a few of the articles, your data is worth a lot of money. It could be worth up to $1,200 dollars. That is something that I find difficult to wrap my mind around, but I do not doubt that it is true. I know that my data is being monitored or shared when I see ads or sponsored posts that seem interrelated to my personal self. These ads are the “creepy” ads that were mentioned in the articles. I liked the analysis of these “creepy” ads and how it relates and takes advantage of our disposition in Western culture in the article “Data ” and the Uncanny Valley of Personalization”:
Personalization appeals to a Western, egocentric belief in individualism. Yet it is based on the generalizing statistical distributions and normalized curves methods used to classify and categorize large populations. Personalization purports to be uniquely meaningful, yet it alienates us in its mass application.
I think the ads are interesting and how they are targeted as stated above, but the bigger picture is an issue of who has our data, what they are doing with it, and how will this affect our privacy. It is said well in “The Convenience-Surveillance Tradeoff”:
“The data is there, and it’s being used, and there isn’t a damn thing most of us can do about it, other than strongly resent it,” one respondent told Pew. “The data isn’t really the problem. It’s who gets to see and use that data that creates problems. It’s too late to put that genie back in the bottle.”
The question that remains is to decide how precious our privacy is, and how much we would be willing to fight for it. I believe most of it is already gone so implementing policy is probably an uphill battle, but probably worth implementing the best change we can make. Personally I use Adblock myself, and since I have started using it have blocked 89,160 ads. I am not sure the ethical standpoint on using this tool; however, I believe I should not be forced to look at ads.
Post 8: Government Backdoors
I think that this is an incredibly complex issue. I think that just reading a few articles on it puts me in absolutely no position to make take a standpoint on the issue. I know this is an ethics class and the idea is to argue a point and use data or scholarly information to make a conclusion on a point–ethical or not ethical. I just think its difficult when there is no ethical side, or when both options are unethical in different reasons.
I thought it was interesting in the article, “Going Dark: Encryption, Technology, and the Balances Between Public Safety” how it explained the government and law as “going dark”:
Thank you for the opportunity to testify today about the growing challenges to public safety and national security that have eroded our ability to obtain electronic information and evidence pursuant to a court order or warrant. We in law enforcement often refer to this problem as “Going Dark.”
I can see that people are concerned about the government’s issues with surveillance and privacy, and they have responded in to those issues. They believe that they have to uphold civil liberties including privacy:
We, too, care about these important principles. Indeed, it is our obligation to uphold civil liberties, including the right to privacy…
We would like to emphasize that the Going Dark problem is, at base, one of technological choices and capability. We are not asking to expand the government’s surveillance authority, but rather we are asking to ensure that we can continue to obtain electronic information and evidence pursuant to the legal authority that Congress has provided to us to keep America safe.
In their eyes nothing will change with regard to the privacy of the American populous. They will still use legal ways to obtain search warrants, etc. The idea is not to expand the government’s surveillance authority, but instead to ensure to give the electronic information to keep America safe.
In the eyes of the government and the DOJ, they admit that the problem is incredibly complex.
Mr. Chairman, The Department of Justice believes that the challenges posed by the Going Dark problem are grave, growing, and extremely complex. At the outset, it is important to emphasize that we believe that there is no one-size-fits-all strategy that will ensure progress.
The issue is that the complexities that they see definitely are not the only issues that could arise from going either way on the security issue. From what I read from these articles, I cannot go ahead and say that the government backdoors are the solution to our national security problem. In the article, “ISIS using encrypted apps for communications; former intel officials blame Snowden (Updated)” we saw that these taps might not be the magical solution that the government once thought they could be.
But even if the US government were to press forward a demand for companies such as Apple, Facebook, and Google to provide a way to tap into message traffic, that would do little to prevent the use of existing peer-to-peer encryption and other encrypted social media tools by terror organizations.
Alongside that, in the article “F.B.I. Director Repeats Call That Ability to Read Encrypted Messages Is Crucial” we saw that this might be a premature avenue to approach a change in national surveillance and privacy. Everyone is still left worried and vulnerable after the Paris attacks, it seems like a time where rash decisions could be made that could completely alter the entire precedent that the government could take when evaluating ethical methods of enforcing security.
Some security experts and cryptographers said some officials were trying to use the Paris attacks to push their agenda.
My understanding is not combatting the argument that “If you’ve got nothing to hide, you’ve got nothing to fear” argument. My idea of this, is that it is too rash to make a decision right now on policy before a robust security system can be created to protect everyones sensitive information. Secrets are security. The government, even though are in a position to do a lot of good, could also do a lot of bad if legislation makes it mandatory for the companies such as Apple and Google to allow government backdoors. At this point, if the government is allowed in a backdoor. The same terrorists and criminals that we are trying to stop will also be able to utilize these weakened security measures.
I am looking forward to learning more about this in class so that I can make a more informed answer to these questions. This is my response based off of my first exposure and understanding to this ethical dilemma.
